idea, solution, data, std from 1kri.
将 $1$ 定为树的根。
考虑一棵怎样的树满足最大独立集大小恰为总点数的一半。
将树黑白染色,奇数层的点染成黑色,偶数层的点染成白色,则所有黑点和白点都构成独立集,且它们至少有一个大小为总点数的一半。如果树满足条件,则它们大小都为总点数的一半。
假设树满足条件,我们考虑深度最深的点,可以证明它没有兄弟节点。
假设它是黑点,那么我们取出白点集合,将它的父亲删去并将它和它的所有兄弟加入,依然能得到一个独立集。如果它有兄弟节点,则这个独立集的大小就大于总点数的一半了,树也就不满足条件了。
那么我们将这个点和它的父亲节点划为一组,在每个最大独立集中,一组内都恰会选择一个节点。将这一组节点从树中删去,得到一棵新的树。容易发现如果原树满足条件则新树也满足条件。
对新树不断重复找最深点、划分组、删去组的操作,一定能将树删空,并得到 $\frac{n}{2}$ 组节点。
不难发现,能划分出 $\frac{n}{2}$ 组是树满足条件的充分必要条件。
在上述的叙述中,组其实就是匹配,我们找到的条件就等价于树存在完美匹配。可以直接将树看作二分图,如果知道二分图最大独立集等于点数减去最大匹配,那么直接就能得到这个条件了。
接下来考虑怎么计数。
发现树的完美匹配(划分组)方案唯一,那么可以直接计数完美匹配数量。
我们设 $f_{i,0/1}$ 表示 $i$ 子树内选择了一个连通块,且 $i$ 是否被划分进组里($1$ 表示被划分进去)。最后的答案就是所有 $f_{i,1}$ 之和。
$\text{dp}$ 直接转移是简单的,我们依次枚举儿子,并与当前节点的状态合并。
但是一些做法可能会遇到计算 $0$ 的逆元的情况,需要特殊处理。感谢 JohnVictor 和 skip2004 指出这种情况并构造了相应数据卡掉。
时间复杂度:$O(n)$。
idea, solution, data, std from tzc_wk.
解法一
暴力枚举执行的计划的集合及顺序,时间复杂度 $O(m!L)$,期望通过 subtask 1。
解法二
考虑按位贪心,问题转化为如何 check 一个前缀是否合法,即,是否能够得到一个序列 $b$ 满足 $b$ 的前 $i$ 位分别是 $c_1,c_2,\cdots,c_i$。
考虑把操作过程倒过来,可以变成这样的过程:维护另一序列 $d$,初始 $d_j=\begin{cases}c_j&(j\le i)\\-1&(j>i)\end{cases}$,每次选择一个操作 $k$,满足 $\forall l_k\le j\le r_k$,要么 $d_j=-1$,要么 $d_j=x_{k,j-l_k+1}$,并将 $l_k\le j\le r_k$ 都改成 $-1$。如果最终 $\forall 1\le i\le n$ 都有 $d_i=-1$ 或 $d_i=a_i$,那么这个前缀就是合法的,否则就是不合法的。
直接模拟上面的过程可以实现 $O(nL)$ 地检验一个前缀是否合法,而因为最终每一位可能的取值的个数之和是 $O(n+L)$ 的,所以最多进行 $O(n+L)$ 次检验,总复杂度 $O(nL(n+L))$,期望通过 subtask 1,2。
解法三
考虑在解法二的基础上优化检验的过程。对于每一种计划我们动态地维护当前状态下失配位置的个数并用一个队列维护失配位置个数为 $0$ 的操作集合,每次取出队列中的某个操作 $k$ 并将 $[l_k,r_k]$ 的位置改成 $-1$。将一个位置 $j$ 改为 $-1$ 的时候我们直接遍历所有 $l_k\le j\le r_k$ 的所有操作并更新其失配位置数,如果变成 $0$ 了就加入队列。这样更新总次数为 $O(\sum\limits r_i-l_i+1)=O(L)$,即可实现 $O(L)$ 进行单次检验,总复杂度 $O(L(n+L))$,期望通过 subtask 1,2,3。
解法四
考虑 subtask 4 怎么做。观察到一个性质是,我们在检验 $c_1,c_2,\cdots,c_i$ 这个前缀是否合法时,我们逐位确定的过程已经保证了 $c_1,c_2,\cdots,c_{i-1}$ 这个前缀已经是合法的了,换句话说,如果仅仅只将 $d_i$ 改成 $-1$ 就必定可以到达合法状态。于是问题转化为我们能否想方设法执行一次 $l_k\le i\le r_k$ 的操作将 $d_i$ 改为 $-1$。
可以发现我们的过程是这样的:先不断执行 $r_k < i$ 的操作直到没有多余的 $r_k < i$ 的操作可以进行为止,然后看看现在能不能执行某个 $l_k \le i \le r_k$ 的操作,如果这时候还不行那就没办法了。因此考虑动态地维护不断执行 $r_k < i$ 的操作以后的 $d$ 并按照解法三的方式维护每个操作的失配位置数。因为 $a_i=0$ 且 $x_i > 0$,所以如果存在经过 $i$ 的操作,我们必然会执行至少一次经过 $i$ 的操作,否则答案第 $i$ 位必然是 $0$。因此我们考虑枚举执行了哪个经过 $i$ 的操作,设为 $k$,如果该操作目前失配字符数为 $0$ 则说明答案第 $i$ 位可以是 $x_{k,i-l_k+1}$。这样可以求得答案第 $i$ 位的值。之后我们遍历所有 $r_k=i$ 的操作看看能不能执行,这个过程中可能会产生连锁反应,即执行某些 $r_k=i$ 的操作以后让之前不能执行的操作变得可执行,不过用解法三的方式仍然可以做到 $O(n+L)$ 地维护这个过程。
总时间复杂度 $O(n+L)$,期望通过 subtask 4。
解法五
subtask 5 相较于 subtask 4 多了初值,因此在解法四的基础上,我们只用考虑如何检验在前缀固定的情况下能否不执行经过 $i$ 的操作。这等价于只进行 $r_k < i$ 的操作能否到达合法状态,即是否最终所有 $d_k\ne -1$ 的 $k$ 都有 $c_k=a_k$。在解法四中我们已经维护出不断进行 $r_k < i$ 的操作后的 $d$,因此我们只需顺便维护 $d_k\ne -1$ 且 $c_k\ne a_k$ 的 $k$ 的个数即可。时间复杂度 $O(n+L)$,期望通过这道题。
idea, data, std, from cmll02, solution from cmll02 zhoukangyang.
subtask 1
枚举集合 $S$,check 生成出的 $b$ 是否正确。
如何生成 $b$?从左往右一个一个填,如果是非前缀最大值肯定填剩余数中的最小值;对于是前缀最大值的那些位置,我们肯定是要填一个尽量小的能填进去而不至于让后面无法复合要求的数。
一个可能的实现方法是:填一个数进去之后,把剩余没填的数中最大的那些分配给剩下没填的前缀最大值,然后把剩下的数从小到大填到非前缀最大值的位置,并检查此时是否每个位置都满足 $c$ 的限制。
时间复杂度 $O(2^n\operatorname{poly}(n))$。
期望得分 $5$。
subtask 2
留给可能存在的 $O(n^3)$ 或者奇怪的 $O(n^2\log n)$。
subtask 3
留给可能存在的复杂度依赖前缀最大值个数 $cnt$ 的做法(如 $O(n^2cnt))$。
这档分 $n$ 开的有些过大,使得场上写这一部分分的选手 TLE 了,在此谢罪>_<。
subtask 4
在这个 subtask 中我们现在知道整个序列中唯一的前缀最大值是第一个元素,显然这意味着一定有 $a_1=n$,所以 $1$ 这个位置是否无法辨认是不重要的(也就是对答案有一个 $\times 2$ 的贡献)。
考虑先鱼如何从无法辨认的 $a$ 和 $c$ 还原出 $b$?只要保证 $b_1=n$ 则不管后面的数怎么填,都符合古籍记载。其中字典序最小的方案,就是将剩余未出现的数从小到大排序后从左往右依次填入每个位置。
这就说明 $2\sim n$ 中无法辨认的位置满足这些位置对应的子序列一定是单调上升的!dp 计算上升子序列个数并乘上 $1$ 位置的两倍贡献即可得到答案。
时间复杂度 $O(n^2)$ 或 $O(n\log n)$(使用树状数组等优化 dp)。
期望得分 $10$。
subtask 5
我们沿用 subtask 4 的分析,可以发现对于非前缀最大值,对应的无法辨认位置仍然需要满足上升,否则存在逆序对,交换这个逆序对一定仍然符合古籍记载,且字典序更小。
如何分析前缀最大值位置呢?注意到一个必要条件,对于前缀最大值位置 $i$,如果它不可辨认,就不能存在一个不可辨认的位置 $j$ 满足 $j > i\land b_j < b_i$,且交换 $b_i,b_j$ 后仍然符合古籍记载。
记 $i$ 右侧的第一个前缀最大值位置是 $x$,$b_{1,\cdots,x-1}$ 中的次大值为 $v$(最大值显然就是 $b_i$)。
若 $b_j\ge b_x$,交换完之后 $b_i > b_x$,$x$ 位置不再是前缀最大值,所以这样的 $j$ 一定没用。
若 $b_j\le v$,交换后 $i$ 位置要么不在是前缀最大值,要么 $v$ 所在位置不应是前缀最大值而交换后变成了前缀最大值,不符合古籍记载,所以这样的 $j$ 也没用。
若 $v < b_j < b_x\land j\neq i$,此时 $j > x$,交换 $b_i,b_j$ 后一定符合古籍记载!
也就是说如果 $i$ 无法辨认,则满足 $v < b_j < b_x\land j\neq i$ 的 $j$ 必须可以辨认。
这个条件是充分的:从左往右每次填一个最小的能填的数时容易证明,满足上面两个条件时,$b$ 一定是字典序最小的方案。
接下来考虑计算方案数。对于前缀最大值来说,他们是否遗失是互相独立的。可以理解为每个前缀最大值划定了一个代表区间,当确定了非前缀最大值无法辨认位置的集合 $T$ 之后,如果一个代表区间里不包含 $T$ 中的任何元素,那么他会带来 $\times 2$ 的系数。
设计 $dp_i$ 代表当前最后一个无法辨认的非前缀最大值位置为 $i$,则转移有 $dp_i2^{f(b_i,b_j)}[b_i < b_j]\to dp_j$,其中 $f(i,j)$ 代表区间 $(i,j)$ 里包含了多少个代表区间。
时间复杂度 $O(n^2)$。
期望得分 $65$。
subtask 6
留给可能的 $n\times cnt$ 做法。
subtask 7
注意到代表区间两两不交。
使用树状数组优化 dp,转移时分类讨论一下当前位置是否在某个代表区间上。
时间复杂度 $O(n\log n)$,期望得分 $100$。
idea from huahua.
std, data, solution from Kubic
方便起见,我们不妨令路径长度不重复。有重复的情况只需在此基础上加一些判断。
令 $P(u,v)$ 为 $u$ 与 $v$ 之间的路径经过的点集,$M(u,v)$ 为 $u$ 与 $v$ 的路径中点(可能在一条边中间,此时新标一个点)。
扫描区间右端点 $r$,维护所有左端点 $l$ 对应的 $f(l,r)$。
令 $(u,v)$ 为关键点对当且仅当 $u < v$ 且 $dis(u,v)=f(u,r)$,令一个点为关键点当且仅当它在至少一个关键点对中。
将所有关键点对按照 $u$ 从小到大排序,令第 $i$ 个点对为 $(u_i,v_i)$,则有:
这可以通过考虑固定 $r$ 移动 $l$ 的过程进行说明。
令一段 $v_i$ 相等的关键点对组成一个 block,令其中 $u_i$ 的最小值为 block 的开头,$v_i$ 为 block 的末尾。
由上述结论,对于一个 block,上一个 block 的末尾等于它的开头。
考虑从 $r$ 移动到 $r'=r+1$ 时关键点对结构如何变化。先找到最小的 $p$ 满足 $(p,r')$ 为关键点对。
结论 $1$:若 $u$ 在 $r+1$ 处为关键点,则 $u=r+1$ 或 $u$ 在 $r$ 处也为关键点。
证明:$u$ 在 $r$ 处为关键点当且仅当 $f(u,r)>f(u+1,r)$,则结论显然。
结论 $2$:$p$ 一定为某个 block 的开头。
证明:
显然存在唯一的 $i$ 满足 $u_i=p$,且关键点对 $(u_i,v_i)$ 所在的 block 开头结尾分别为 $a,b$。
若 $p\neq a$,则可以发现 $a,p$ 均在 $M(p,b)$ 同侧($dis(a,b)>dis(p,b)$),$b,r'$ 在另一侧($dis(p,r')>dis(p,b)$)。由此可以导出 $dis(a,r')>dis(a,b),dis(a,r')>dis(p,r')$,这与 $p$ 的最小性矛盾。
因此 $p=a$。
假设我们已经得到 $p$。
考虑以 $p$ 为末尾的 block,令 $a$ 为这个 block 的开头。可以发现若 $a$ 不为第一个关键点,则 $(a,p)$ 依然为关键点对。证明方法与结论 $1$ 类似。因此 $a$ 前面的部分均不变。只需要在当前 block 中删除所有 $dis(u_i,v_i) < dis(p,r')$ 的关键点对。
$p$ 后面的部分会合并为一个开头为 $p$,末尾为 $r'$ 的 block。由结论 $1$,我们只需要删除其中的一部分关键点,剩余关键点均与 $r'$ 形成关键点对。
保留的关键点对应了与 $r'$ 距离的后缀最大值。
结论 $3$:关注 $p$ 后面的一个 block,一定是删除一段后缀的关键点(不包括 block 的末尾)。
证明:
令这个 block 的开头和末尾分别为 $a,b$,令 $a$ 与 $b$ 的路径上离 $r'$ 最近的点为 $c$。
从后往前依次考虑这个 block 中的每个关键点对 $(u_i,b)$,由直径性质可得 $M(u_i,b)\in P(a,b)$,且 $dis(M(u_i,b),b)$ 递增。
若 $M(u_i,b)\in P(b,c)$,则 $dis(b,r')=dis(b,M(u_i,b))+dis(r',M(u_i,b))=dis(u_i,M(u_i,b))+dis(r',M(u_i,b))>dis(u_i,r')$。因此这些 $u_i$ 一定全部被删除。
删除这段后缀之后,剩余的 $u_i$ 一定满足 $M(u_i,b)\in P(a,c)$。此时 $dis(u_i,r')-dis(u_i,b)=dis(c,r')-dis(b,c)$,为与 $i$ 无关的常数。
之前的结构保证了 $dis(u_i,b)$ 递增,因此 $dis(u_i,r')$ 递增,被删除的一定为一段后缀。
这些有关两点间距离的式子看起来很可怕,但实际上画个图毛估估一下就很好理解(
考虑直接暴力执行上述算法,即:
求 $p$ 的过程中暴力从后往前扫,一但不合法就停止。
对于末尾 $\ge p$ 的每个 block 暴力地从后往前依次判断每个关键点是否删除。
对于一个 block,其中没有被删除的部分增加量均一致,因此可以 $O(1)$ 得到对答案的影响。
每次判断均需要 $O(1)$ 次询问。
其询问次数复杂度正确的关键原因在于 $p$ 后面的部分均会被合并到同一个 block 中。
直接暴力地实现即可做到时间复杂度 $O(n^2)$,询问次数 $O(n)$。用链表维护即可将时间复杂度优化到 $O(n)$。
在本题中,为避免重复询问增大常数,需要对询问进行记忆化。
关于常数的分析,目前 std 可以估计出一个非常粗略的上界 $8n$。但笔者造了许多类型的数据测试下来均不超过 $5n$。
同时,std 的常数也有一些优化的空间。比如 $[1,r]$ 的任意子区间直径长度均可以通过之前的结构求出,std 为了实现方便,可能会在 $r$ 移动到 $r+1$ 的过程中再调用一些此类询问。
一些题外话:
在给定树结构的情况下,我们将区间直径扫描右端点 $r$,维护每个左端点 $l$ 对应的 $f(l,r)$ 的过程刻画为了 $O(n)$ 次区间加。若使用 $O(n)-O(1)$ RMQ,则我们在 $O(n)$ 的时间复杂度内解决了区间直径和。从区间直径问题的角度来说这是一个相对令人满意的结果。
idea, data from command_block, solution from command_block zhoukangyang, std from zhoukangyang.
题外话:cmd 老师投这题的时是 $m\le 300,n\le 10^{18}$ 的版本。但是我发现如果数据范围是 $n,m\le 2.5\times 10^5$,那么就需要有更多的观察,而且还不需要 FFT,很优雅!于是就改成了现在的版本。
为了方便,在时刻 $0$ 前面加一秒,这一秒等待不会改变沙漏的状态。
令 $n\leftarrow n+1$,这样就转化为 $n$ 秒,时刻 $1,2,\dots,n$ 末尾各可以翻转或不翻转。
算法一
我会暴力!
$O\big(2^n\big)$ 枚举 $s_{1\sim n}$,然后 $O(nm)$ 模拟龙门的行为即可。复杂度 $O(nm2^n)$。
期望通过子任务 $1$,得分 $8$。
算法二
我会状压 DP!
记 $X=(x_1,x_2,\cdots,x_m)$ 表示某一时刻大小为 $1\sim m$ 沙漏的状态。
记 $dp[i][X]$ 表示第 $i$ 个时刻沙漏们状态为 $X$ 的方案数,枚举下一个时刻翻转与否,容易得到 $X$ 的变化,也就容易得出转移。
直接做复杂度是 $O(n(m+1)!)$ 的,如果观察 DP 数组的取值,可以发现只有 $2^m$ 种 $X$ 是有用的,复杂度可以改进为 $O(n2^m)$。
期望通过子任务 $2$,得分 $15$。结合算法一,得分 $23$。
算法三
我会分析性质!
当 $s$ 确定时,记 ${\rm calc}(M)$ 为机器放入容量为 $M$ 的沙漏时的输出。观察其性质。
任取 $s$ 打表观察(或观察样例)可以发现,${\rm calc}(M)$ 是关于 $M$ 的折线,斜率为 $0$ 或 $1$。
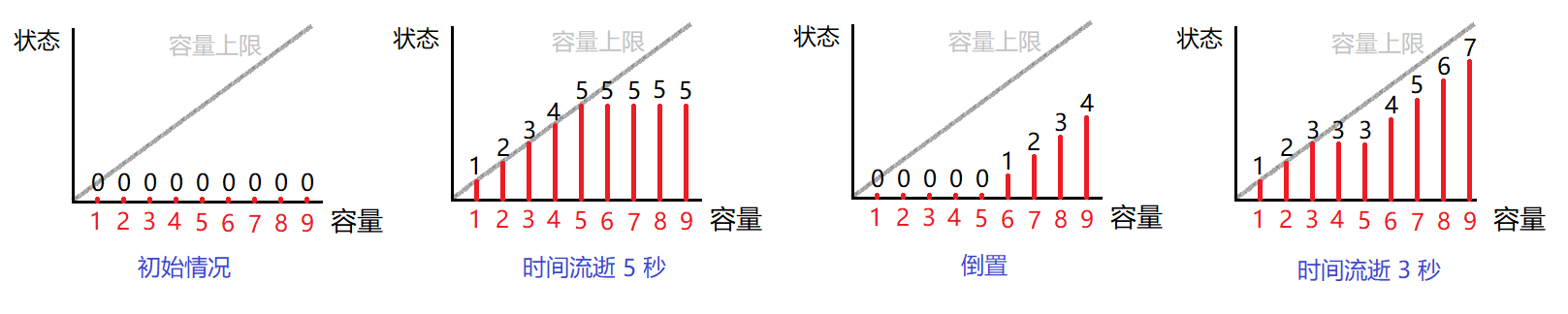
这容易用归纳法证明。
考虑用更简明的方式描述折线。将其差分,记 $w_i={\rm calc}(M)-{\rm calc}(M-1)$(不妨设 ${\rm calc}(0)=0$),则 $w$ 是一个从 $w_1$ 开始的无穷 $01$ 串。
初始时 $w_{1\sim m}$ 为全 $1$。观察机器的操作对 $w_{1\sim m}$ 的影响。
给出的 $x_{1\sim m}$ 相当于确定了 $w_{1\sim m}$ 的末状态。
可以发现,$w_{1\sim m}$ 中 01 连续段的交替之处(即折线的拐点)具有重要地位。假设 $w_{1\sim m}$ 中有若干 01 连续段,某个段的末尾位置是 $t$。
引理:对 $w_t$ 的最后一次操作完成后(称作“锁定 $w_t$”),$w_t$ 及之后的位置都不会再被操作。
证明:因为 $w_t$ 是连续段的结尾,目标中 $w_{t+1}\neq w_t$。
若此时 $w_t=w_{t+1}$,需要想办法修改 $w_{t+1}$,然而因为两者相等且 $w_t$ 在 $w_{t+1}$ 之前,只能先修改 $w_t$,这与“最后一次修改”矛盾。
若此时 $w_t\neq w_{t+1}$,想要修改 $w_{t+1\sim+\infty}$,需要操作时 $w_{1\sim t}=1$,则 $w_{t+1}=0$。只能翻转 $w_{t+1}$,转化为 $w_{t_i}=w_{t+1}$ 的情况。$\square$
记 $w$ 中第 $i$ 个 01 连续段的末尾为 $t_i$。
锁定 $w_{t_i}$ 时,必须保证之后的 $w$ 都已经正确,且根据修改的规则,锁定后必然有 $w_{1\sim t_i}=1$。(锁定后必须瞬间翻转,否则下一秒会改动 $w_{t_i+1}=1$)
这表明,锁定 $w_{t_i}$ 后(包括最后一次翻转后),$w$ 的状态居然是唯一的!具体地,$w_{1\sim t_i}=0$,且后面的部分不能再修改。
于是,我们可以把操作过程分成若干个阶段考虑。
具体地,设 $E$ 为初始状态,$S_i$ 为锁定 $w_{t_i}$ 后的状态,整个操作过程可以分成下列阶段
$$[E,S_k],(S_k,S_{k-1}],\dots(S_2,S_1]$$
其中阶段 $(A,B]$ 表示从状态 $A$ 出发到达状态 $B$,且其中不再回到状态 $A$(可以多次经过状态 $B$)。
对于第 $i$ 个阶段,记花费 $k$ 秒(时刻 $1,2,\dots,k$ 可选择是否翻转)的方案数为 $F_i[k]$。将各个 $F$ 数组加法卷积,即可得到答案。
在 $S_{i+1}$ 中,$w_{1\sim t_{i+1}}$ 都是 $0$。在 $S_i$ 中,$w_{1\sim t_i}$ 是 $0$,$w_{t_i+1}\sim w_{t_{i+1}}$ 是 $1$。
因为 $w_{t_{i+1}}$ 已经锁定,假设我们污染了 $w_{t_i+1}\sim w_{t_{i+1}-1}$ 中的某个 $w_p$,只能再操作一次 $w_p$ 把它改回来。为了这样做,我们会将 $w_{1\sim p}$ 修改到完全一样(都为 $1$)。
取 $p$ 是最右侧被污染的位置,不难发现,一旦产生污染,只能回到初始状态 $S_{i+1}$,故不能有任何污染。所以我们能操作的只有 $w_{1\sim t_i}$。
记 $R=t_i$,记 $x$ 为 $w_{1\sim R}$ 中的 1 的个数,初始时 $x=0$。最终目标是 $x=0$,且翻转次数为奇数。
容易列出 DP:
记 $g[k][c][0/1]$ 为共 $k$ 秒,$x$ 取值为 $c$,翻转次数的奇偶性为 $0/1$ 的方案数,边界是 $g[0][0][0]=1$,有转移
$$
\begin{aligned}
g[k][c][e]&\to g[k+1][c+1][e]&(c< R)\\
g[k][c][e]&\to g[k+1][R-c-1][\neg e]&(c< R)
\end{aligned}
$$
(第二行是先再等一秒再翻转)
其中要 BAN 掉 $g[k][0][0]$,因为这回到了初始状态。最终需要的答案是 $g[k][0][1]$。
假设最右侧的连续段是 $w_{t+1\sim m}$,想要从初始状态到锁定 $w_t$。区别在于,可以随意污染 $w_{m+1\sim +\infty}$。
可以分为两个阶段。
一阶段:从 $w$ 全 $1$ 出发,到达 $w_{1\sim m}=0$,期间允许污染 $w_{m+1\sim +\infty}$。
二阶段:从 $w_{1\sim m}=0$ 出发到锁定 $w_t$,不允许回到 $w_{1\sim m}=0$。
一阶段的 DP 如下:
记 $x$ 为 $1\sim m$ 中 $1$ 的个数,初始时 $x=m$。
记 $g[k][c]$ 为共 $k$ 秒,$x$ 取值为 $c$ 的方案数,边界是 $g[0][m]=1$,有转移
$$
\begin{aligned}
g[k][c]&\to g[k+1][\min(c+1,m)]\\
g[k][c]&\to g[k+1][m-\min(c+1,m)]
\end{aligned}
$$
最终需要的答案是 $g[k][0]$。
二阶段中,若要修改 $w_{m+1\sim +\infty}$,需要 $w_{1\sim m}=1$,而这早晚会变成 $w_{1\sim m}=0$,于是 $w_{t+1\sim +\infty}$ 都不能修改,和上文相同。
(若目标的 $w_{1\sim m}=1$,可以不经过 $w_{1\sim m}=0$ 的阶段,但凑巧不需要特殊处理)
易知 $\sum t_i\leq n$,故连续段个数是 $O(\sqrt{n})$ 的。
求各个 $g$ 的复杂度总和是 $O(n\sum t_i)=O(n^2)$,将它们暴力卷积的复杂度是 $O(n^{2.5})$。
期望通过子任务 $1,3$,得分 $45$。结合算法二,得分 $60$。
算法 $\pi$
$n\leq 10^{18}$ 怎么做?
承接算法三的思路。根据线性递推的结论,$g$ 的 DP 可以看做大小为 $O(R)$ 的矩阵的幂构成的数列,是一个 $O(R)$ 阶线性递推。
使用 BM 算法,可以在 $O(\sum t_i^2)\leq O(m^3)$ 的时间里求出各个 $g$ 的分式形式 $P_i(x)/Q_i(x)$。
将所有分式相乘(用分治 FFT 将分子分母分别相乘),总复杂度 $O\big((\sum t_i)\log(\sum t_i)\big)\leq O(m^2\log m)$。
然后,我们可以得到答案的分式 $P(x)/Q(x)$(上下各有 $O(m^2)$ 项),其远处项系数可以 $O(m^2\log m\log n)$ 求出。
总复杂度 $O(m^3+m^2\log m\log n)$。可以承受 $n\leq 10^{18},m\leq 300$ 的数据范围。
算法四
上面的题解都是 cmd 写的,下面的题解是我写的。所以我们从头开始考虑问题。
我菜,所以很多地方都是毛估估的,毛估估的地方应该也不会影响正确性啥的。
首先,除去最后一步操作,我们可以把沙漏看成是 一个点在数轴上面走,每次 $+1$ 或 $-1$,走的时候对 $0$ 取 max 并对 $m$ 取 min。加上最后一步操作后,需要把所有 $x_i$ 变成 $i-x_i$ 再做一遍。
如果翻转这个 $+1/-1$ 的操作序列,并对操作做前缀得到数组 $a$。画出所有 $(i,a_i)$,我们将得到一张折线图。
考虑给定沙漏的大小 $m$ 时,怎么算沙漏最终的数:从前往后算出 $a$ 的前缀最小值 $premin_i$ 和前缀最大值 $premax_i$。找到第一个 $premax_i-premin_i=m$ 的位置 $i$(没有则取 $n$ 位置),可以发现答案是 $premax_i$。
利用 $v_m=x_m-x_{m-1}$ 的值,我们讨论 $m$ 找到的位置相对 $m-1$ 找到的位置有哪些变化:
如果 $v_i=0$,那么可以是
- $m$ 的 $premax_i$ 被更新了。
- 没有 $premax_i-premin_i=m$ 的位置了。
如果 $v_i=1$,那么只能是
根据给定的答案序列,除去最后一段 $v_i$ 的全 $0$ 段(这一段 $0$ 可能是没有 $premax-premin=m$ 的位置),我们可以知道这个折线前若干次更新 $premin$ 和 $premax$ 的顺序。最后一个全 $0$ 段可以按 $premax_n-premin_n$ 和 $m$ 的大小关系进行分讨。
注意到一次更新 $premin$ 和一次更新 $premax$ 都是走一段有起点终点高度、带上下边界的折线,最终的答案就是将这些折线拼接起来,也就是关于步数的 $\rm OGF$ 相乘。
暴力算可以得到 $\mathcal O(nm^2)$、$\mathcal O(n^2m)$ 或 $\mathcal O(nm\log n)$ 的时间复杂度。以此为基础还能得到一些形如 $\mathcal O(n \sqrt n\log n)$ 的复杂度。
先考虑每一步的 $\rm OGF$ 怎么算。
考虑利用反射容斥,把终点按照边界线反射。反射容斥会将终点反射成很多很多的高度不同的带权终点,并去掉上下边界的限制。
对于一个终点,设其和起点的高度差的绝对值是 $h$,那么其贡献的 $\rm OGF$ 就是 $\sum_{i=0} \binom{2i+h}{i} x^{2i+h}$。利用 广义二项级数 刻画之,得到其 OGF 为 $\frac{(x\mathcal{B}_2(x^2))^h}{-1+2\mathcal{B}_2(x^2)^{-1}}$。
下面的那些锤子是不变的,变的只有上面的东西。我们发现,把这些 OGF 乘起来的时候,其实只用在意这些 $h$ 的总和(而且还只用求前 $n$ 项)。
所以说,我们只需要将这些 $\sum_{h} w_i x^{h_i}$ 乘起来就行了。这个 OGF,其实一定是一些 $x^r(1-x^{a})^{b}$($b$ 是可以为负的整数) 的乘积。
而在分母中,$\frac{1}{-1+2\mathcal{B}_2(x^2)^{-1}}$ 可以被视作是 $\frac{\mathcal{B}_2(x^2)}{-\mathcal{B}_2(x^2)+2}=\frac{\mathcal{B}_2(x^2)}{1-(x\mathcal{B}_2(x^2))^2}$,可以被写成 $\frac{1}{1-x^2}$ 复合 $x\mathcal{B}_2(x^2)$ 和一些额外的 $\mathcal{B}_2(x^2)$。
乘这些 OGF 当然可以用 $\ln-\exp$ 的方法做到 $\mathcal O(n\log n)$,但是实际上 FFT 是可以被避免的!
有结论:最终的 $x^r\prod_i (1-x^i)^{v_i}$ 的 $\sum |v_i|$ 是 $\mathcal O(\sqrt n)$ 级别(含分母中的 $(1-x^2)^{-1}$)。
这是为什么呢?我们发现,对于连续的一段 $0$ 或 $1$,他们贡献的多项式乘起来事实上只有 $\mathcal O(1)$ 项。这里还有一个更直观的理解:一段连续的 $0/1$ 可以被合起来,合成一个反射容斥。
而新连续段开启的时候,即 $v$ 数组 $01$ 交替的时候,设交替位置为 $t$,那么一定需要 $t$ 的时间来交替,所以有解时交替的次数只有 $\mathcal O(\sqrt n)$。
在处理最后一段 $0$ 的时候,分 $premax_{n}-premin_n\ge m$ 和 $premax_{n}-premin_{n} < m$ 分开计算。第一类就是按前面的做法做整个字符串,随后乘 $\frac{1}{1-2x}$ 的生成函数。这个东西也可以看成成终点任意的 GF,也可以写成一个多项式复合 $x\mathcal B(x^2)$,处理方法和反射容斥类似;第二类的最后一段则相当于是乘 起点固定、终点不固定、有上下界的反射容斥。仍然可以类似终点固定地做,通过一些精细的观察也可以线性加入其贡献。
最后我们需要求的是 $[x^n]\sum_{i} v_i x^{i+b} \mathcal B(x^2)^{i+a}$ 状物,利用一些广义二项级数的结论就可以简单计算。
时间复杂度 $\mathcal O(n \sqrt n)$(不需要 FFT) 或 $\mathcal O(n \log n)$ 或 $\mathcal O(n\log^2 n)$,期望得分 $100$。






 鄂公网安备 42010202000505 号
鄂公网安备 42010202000505 号